Par Nicolas Gambardella
Covid-19 nous affecte tous de manière quotidienne et les discussions autour de la maladie déchaînent les passions, que ce soit chez les politiques, les professionnels de la santé, les scientifiques ou le grand public. Commentaires et débats, en particulier en ce qui concerne la gravité de la pandémie et la façon de la contrer, sont souvent entachés d’inexactitude voire de mauvaise foi du fait de la confusion entre différents concepts et de l’incompréhension de certains d’entre eux. On parle de choses différentes, on compare des choses qui ne sont pas comparables et on détourne les propos des autres.
Je ne suis ni médecin ni épidémiologiste. Mes opinions n’engagent que moi, et je ne suis certainement pas en position de fournir des conseils. Ce billet n’a donc pas pour vocation de prendre position mais d’apporter une certaine clarté sur les concepts balancés de-ci de-là au gré des articles de presse et des tweets rageurs.
Covid-19 et SRAS-CoV-2, est-ce la même chose ?
Non, Covid-19 et SRAS-CoV-2, ne sont pas deux noms désignant la même chose. En effet, Covid-19 est une « maladie », c’est-à-dire un ensemble de symptômes reliés à une cause commune identifiée (par opposition à un « syndrome » qui serait un ensemble de symptômes dont la cause est inconnue, incertaine ou non pertinente). Cette maladie est due à l’infection des humains par le virus SRAS-CoV-2. Cette infection est la cause déclenchant la maladie, ce n’est pas la maladie. Une partie importante de la population n’exhibe aucun symptôme après l’infection par SRAS-Cov-2, on dit que les personnes sont « asymptomatiques ». En d’autres termes, ces personnes ne sont pas malades. Selon les études, cette population est estimée entre un tiers des personnes infectées à plusieurs fois les personnes déclenchant la maladie.
On voit donc qu’il y a une grande différence de gravité selon qu’on parle de l’infection par le virus ou de la maladie. L’infection par le SRAS-CoV-2 n’est globalement pas très grave, comparée par exemple aux infections par le virus Ebola ou le virus de la rage. En revanche, du fait des symptômes respiratoires sévères et de l’absence de traitements, la maladie Covid-19 est plus dangereuse que la rage.
La maladie est diagnostiquée sur la base des symptômes, avant hospitalisation, durant l’hospitalisation or post-mortem. Seule une certaine proportion des patients est testée pour la présence du virus. Il est généralement admis que chez tous les patients présentant les symptômes de Covid-19 et positifs pour le virus, celui-ci est le facteur déclenchant de la maladie. Mais il faut se rappeler que nous sommes tous infectés en permanence pas plusieurs virus (parfois plusieurs souches du même virus). Pour les patients non-testés pour la présence du virus, la décision dépend des politiques locales. D’où par exemple les débats sur la très faible mortalité par Covid-19 en Russie, ou sur la place des décès en maisons de retraite.
En conclusion, toutes les personnes infectées par SRAS-CoV-2 ne sont pas malades de Covid-19, et il est possible que chez une petite partie des personnes diagnostiquées comme malades de Covid-19 (en particulier dans les diagnostics post-mortem) la maladie n’ait pas été déclenchée par SRAS-CoV-2.
Plus haut, j’ai utilisé de mot « mortalité ». Il est donc temps de faire un petit point sur le vocabulaire.
Mortalité, Létalité, taux de létalité par cas, taux de létalité par infection
La « mortalité » d’une maladie représente le nombre de personnes tuées par cette maladie dans une population donnée, incluant les personnes non atteintes de la maladie. La « létalité » d’une maladie représente le nombre de personnes tuées par cette maladie au sein des patients atteints. La létalité d’une maladie ne dépend pas de sa « prévalence », ce qui est le cas de la mortalité. Dans la plupart des pays, la grippe saisonnière a un taux de mortalité beaucoup plus élevé que la fièvre hémorragique due à Ebola, bien que cette dernière ait un taux de létalité bien plus élevé.
Afin d’estimer le taux de létalité d’une maladie infectieuse, il faut mettre en correspondance les valeurs observées de décès dans la population malade. La valeur observée est le taux de létalité par cas (CFR, pour Case Fatality Ratio). La valeur estimée est le taux de létalité par infection (IFR, pour Infection Fatality Ratio). On pourrait croire qu’avec une évaluation bien construite et attentive ces nombres sont proches. Il n’en ait rien. La première raison est décrite dans le paragraphe précédent (différence entre détection de l’infection et diagnostic de la maladie). La seconde est que le taux de létalité par cas évolue au cours du temps. Les premiers malades diagnostiqués présentent généralement des formes sévères, avec une mortalité élevée. Le taux de létalité observée est donc très élevé (un cas extrême étant 100 % si le premier malade meurt). Au fur et à mesure que le diagnostic est étendu à une population plus large, et que la prise en charge des malades s’améliore, la proportion de personnes survivant à la maladie augmente. Et le taux de létalité par cas se rapproche du taux de létalité par infection, autrement dit du « vrai » taux de létalité. On peut observer cette évolution sur l’image ci-dessous, représentant l’issue des maladies Covid-19 en Espagne (Source https://www.worldometers.info/coronavirus/country/spain/, le 23 mai 2020). Le premier malade a guéri, puis pendant toute une période, 50 % des malades sont décédés, ce qui correspond à peu près à la fraction de décès des patients Covid-19 sous ventilateurs. Le taux de rétablissement augmente dès lors de manière plus ou moins régulière.
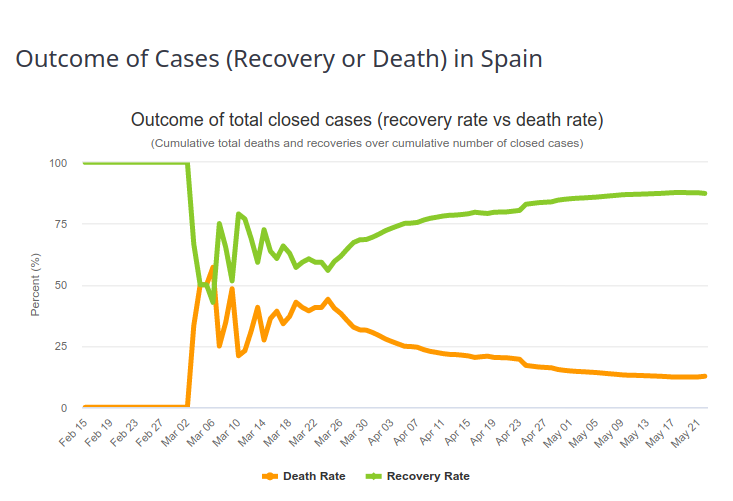
Il est très important de comprendre que si 10 % des patients diagnostiqués pour Covid-19 dans une région donnée et à une période donnée décèdent de la maladie, cela ne signifie absolument pas que 10 % des personnes infectées par le virus vont en décéder.
Peut-on comparer la létalité entre pays ? Influence des politiques de test
Afin d’évaluer les taux de létalité par infection, il faut bien entendu mesurer les taux de létalité par cas, et pour ce, être à même de détecter les cas. Il y a deux types de test.
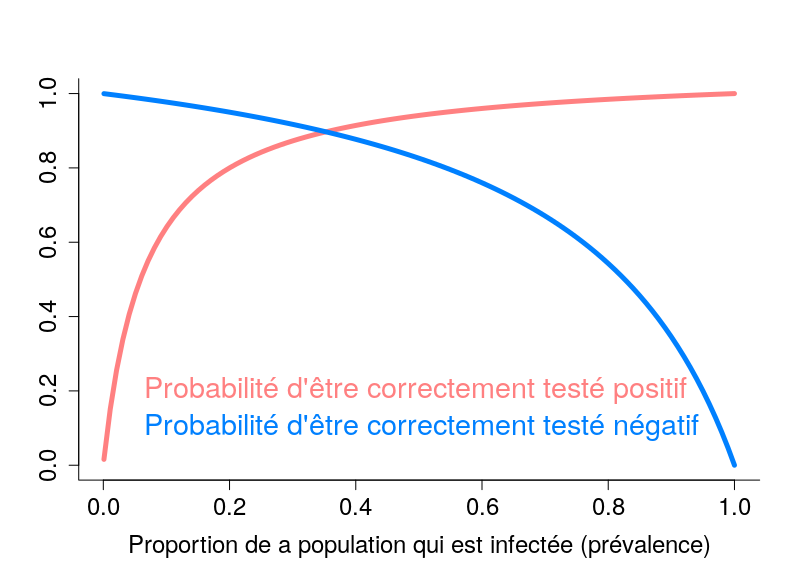
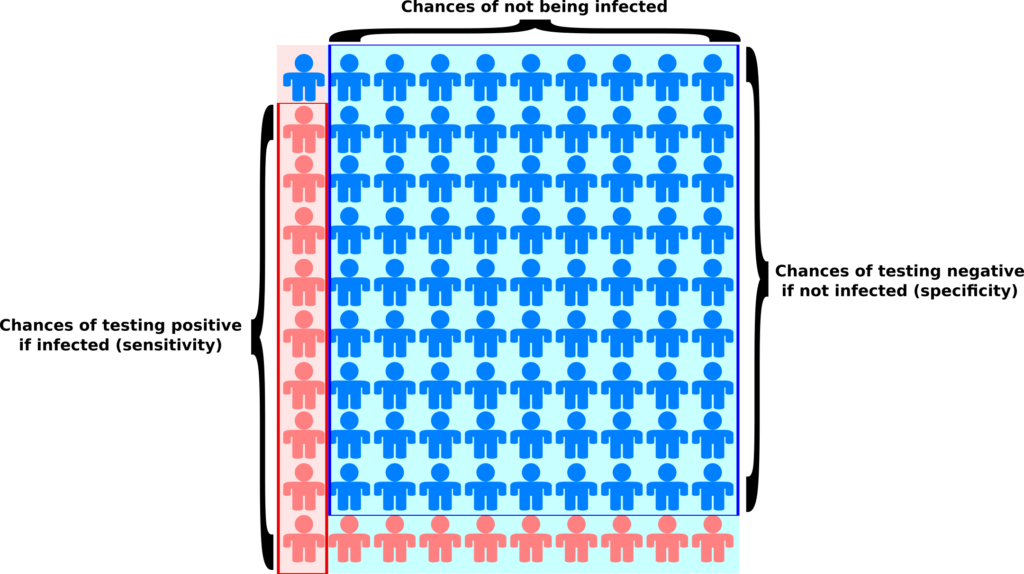
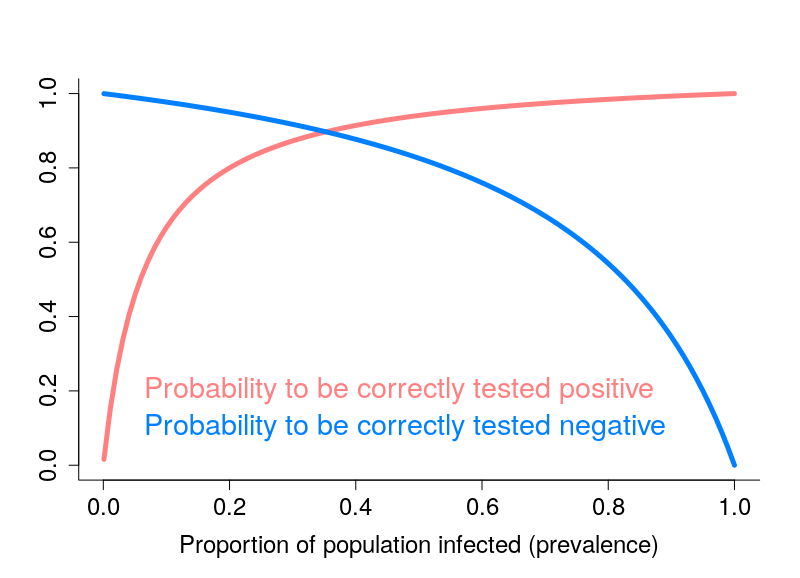
Les tests dits sérologiques détectent la présence dans le sang d’anticorps ciblant le virus. Ces tests permettent de savoir si une personne a été infectée par le passé. Ils présentent deux problèmes principaux. Premièrement, à l’heure actuelle, on ne sait pas exactement quelle proportion des personnes infectées crée des anticorps. Pour les personnes infectées ayant développé Covid-19, il semble que la quantité d’anticorps soit liée à la sévérité des symptômes (probablement car ces derniers sont liés à la quantité de virus, la « charge virale »). La grande inconnue concerne les personnes n’ayant pas développé la maladie. Deuxièmement, ces tests ne sont généralement pas très fiables, et en particulier leur « sensibilité » n’est pas suffisamment élevée (plus de détails dans ce billet).
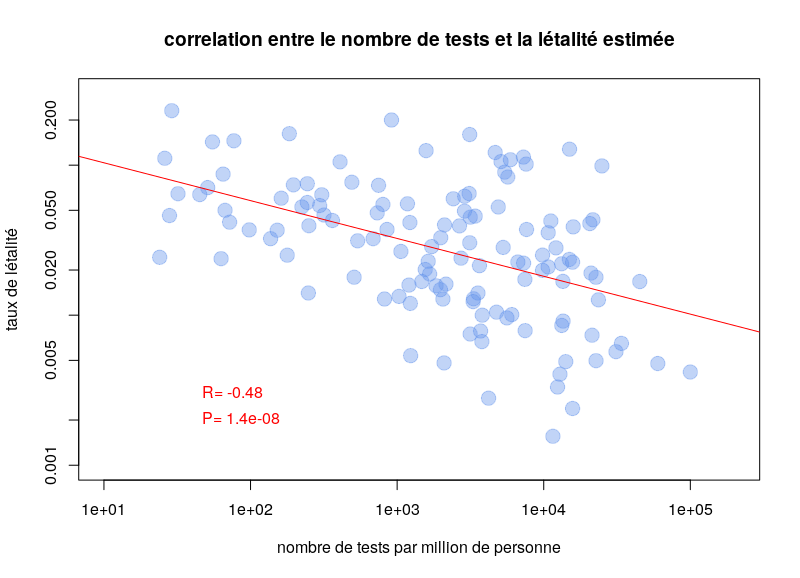
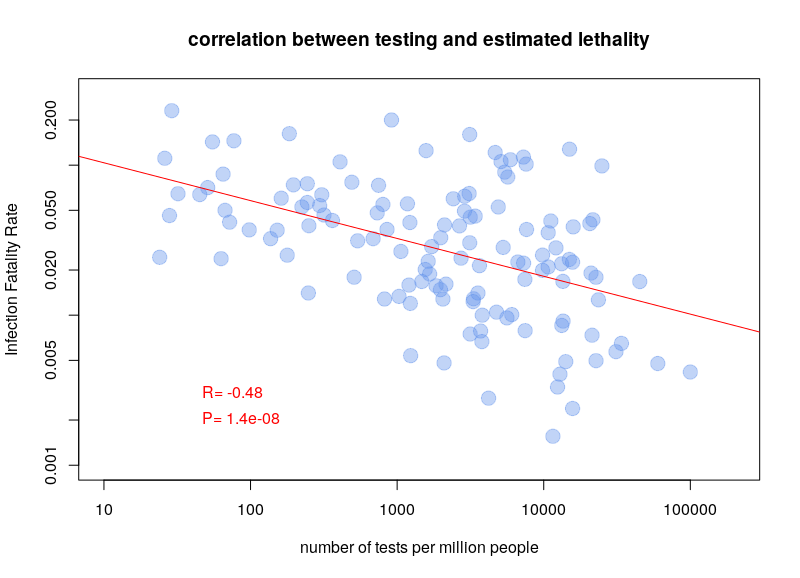
L’autre type de test consiste à détecter la présence du virus chez les gens activement infectés. Le problème de ces tests est qu’il faut les refaire continuellement. Pendant quelques jours après l’infection, la charge virale n’est pas suffisante pour être détectée. De plus, après quelques semaines, le virus n’est plus détectable. Une personne ayant présenté des symptômes de Covid-19 peut maintenant être négative. Ce type de test est néanmoins celui utilisé pour calculer les taux de létalité par cas. Il est dès lors clair que la politique de test va influencer les calculs. Si un pays ne test que les personnes entrant à l’hôpital, le taux de létalité va être plus important que si un pays teste la population dans son ensemble. Il n’est donc pas surprenant qu’on observe une corrélation très nette entre les taux de létalité par cas et le nombre de tests effectués par million d’habitants. Le graphe ci-dessous est basé sur les données de Worldometer du 10 avril 2020.
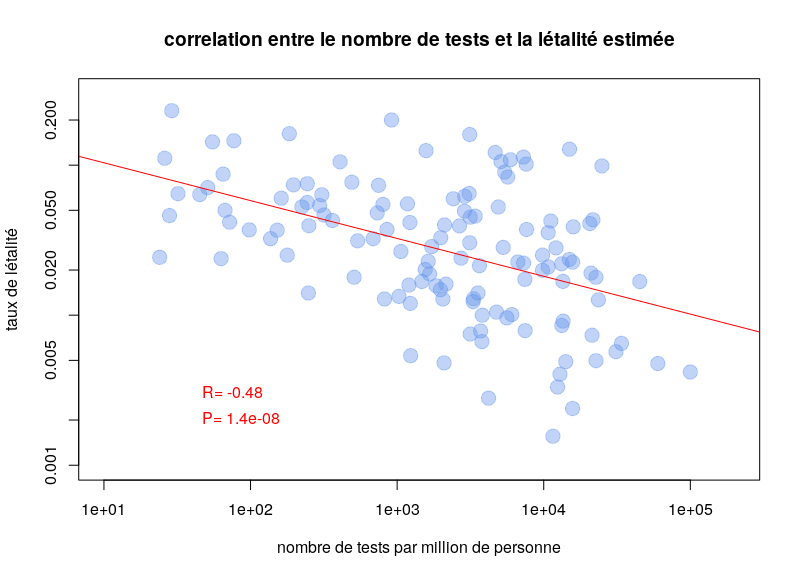
Peut-on comparer la létalité entre pays ? Influence de l’espérance de vie
Différentes études ont tenté de calculer un taux de global de létalité de Covid-19 pour l’ensemble de la population, voir par exemple ici, ici, et ici. Ces estimations sont basées sur des données obtenues par différentes méthodes (par exemple, diagnostic de la maladie, détection du virus, détection des anticorps contre le virus) dans des régions disparates, et analysées de manière variées. Il n’est pas surprenant que les résultats soient pour le moins hétérogènes. Ce qu’elles ont en commun est de vouloir déterminer un taux « universel ». Vouloir attacher à une maladie un taux de létalité unique, est une opération toute à faire justifiable. Cependant, ce taux ne peux être valable que pour une population homogène et va nécessairement varier entre populations, rendant les comparaisons difficiles, voire non pertinentes.
Le premier facteur est l’effet de l’âge. La plupart des maladies respiratoires affectent de manière disproportionnée les personnes âgées. De ce fait, les infections par les virus déclenchant ces maladies, comme les grippes, montre une mortalité extrêmement dépendante de l’âge. De manière similaire, une estimation du taux de létalité de Covid-19 en Chine était de 0,0016 % pour les enfants de 0 à 9 ans et croissait progressivement jusqu’à 7,8 % pour les plus de 80 ans, soit un accroissement de près de 5000 fois.
Si la létalité dépend le l’âge, c’est bien également le cas de la mortalité. Cependant, la relation n’est pas directe du fait de la distribution de la population par classe d’âge (la « pyramide des âges »). Il y a beaucoup plus de personnes âgées de 60 à 85 ans que de 85 à 110 ans. Bien que Covid-19 soit beaucoup plus létale dans la seconde population, il y a plus de mort dans la première. Différents pays ayant des pyramides des âges différentes, cela affectera leur taux de létalité estimé global, comme le montre la figure ci-dessous (empruntée de https://theconversation.com/the-coronavirus-looks-less-deadly-than-first-reported-but-its-definitely-not-just-a-flu-133526)
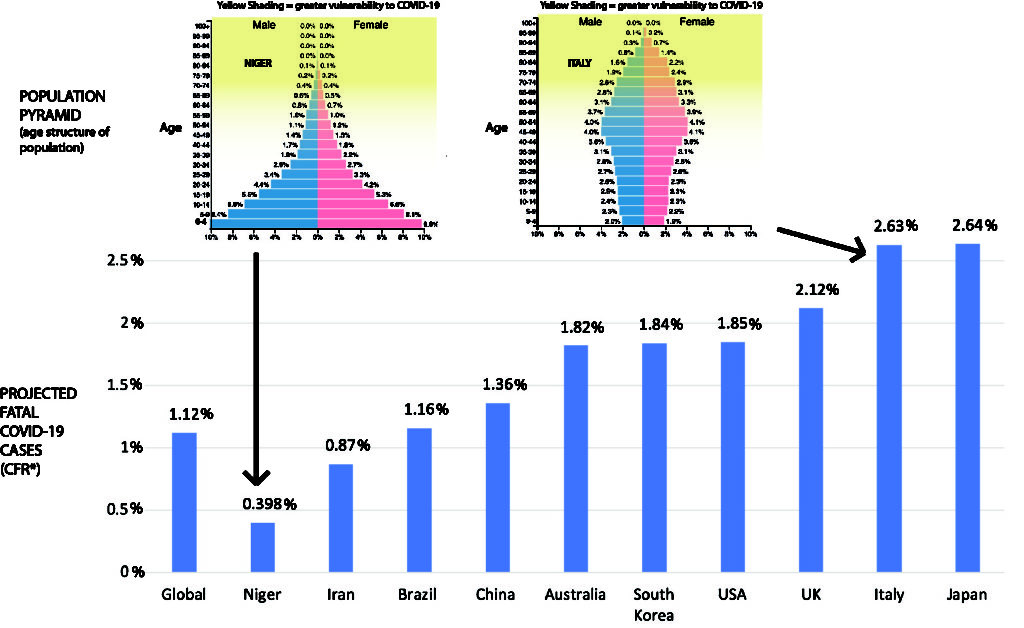
Oui, mais attention, ce raisonnement n’est pas si simple. Comme le montrait déjà l’ONU en 1955, la courbe de mortalité globale est affectée par l’espérance de vie. La mortalité à 25 ans dans un pays dont l’espérance de vie est de 60 ans, est la même que la mortalité à 45 ans dans un pays dont l’espérance de vie est de 70 ans. Cela est dû aux causes sous-jacentes de l’espérance de vie plus faible. Ce qui nous amène aux comorbidités.
Peut-on comparer la létalité entre pays ? Influence des comorbidités
Stricto-sensu, les comorbidités sont les autre troubles qui vont affecter l’issue de la maladie. Mais ici j’entends par là tous les facteurs non liés à l’infection par SRAS-CoV-2 qui vont affecter le taux de létalité de Covid-19. Un papier a étudié un grand nombre de ces facteurs sur une grande cohorte de plus de 96000 patients venant de six continents (le but de l’étude était d’étudier l’effet de médicaments sur Covid-19, mais cela n’est pas le propos ici). Si chaque année de vie accroît le risque de décès par Covid-19 de 1 %, un point d’indice de masse corporelle l’accroît de 6 %, avoir du diabète de 20 %, fumer de 27 % et être d’origine hispanique de 50 % ! Ces différents facteurs ne sont bien entendu pas indépendants (et du coup non additifs).
L’impact de l’origine ethnique peut venir en partie des facteurs de prédisposition génétiques, ainsi que des conditions environnementales. Il est par exemple clair que la transmission de SRAS-CoV-2 est affectée par la température et l’humidité ainsi que la pollution atmosphérique. Il n’est pas impossible que l’issue de la maladie en soit également affectée (possiblement via des comorbidités respiratoires).
Enfin, l’état des systèmes de santé a un impact considérable sur le nombre de décès par Covid-19. Si la plupart des malades n’ont que des symptômes légers (sans même parler des personnes asymptomatiques), une fraction des patients nécessitent une aide respiratoire. Dans le pire des cas, ces personnes doivent être intubées. Une fraction importante de ces dernières survivent. Dans les systèmes de santé n’ayant pas une capacité de ventilateurs suffisante, tous ces patients décèdent. Et ce indépendamment des politiques entreprises pour contenir ou éradiquer la maladie. Cependant, ces politiques sont importantes pour maintenir le nombre de malades atteints de la forme sévère de Covid-19 en deça des limites du système de santé (« aplanir la courbe »).
Immunité collective ou politiques d’isolation
Une des sources inépuisable de débat stériles et acrimonieux est la bataille entre partisans de l’« immunité collective » (aussi appelée immunité grégaire ou de groupe) et ceux de l’«isolement». Cette dernière notion est familière à tout le monde, et assez simple à comprendre. Si on isole les gens, via les gestes barrières et le confinement, ils ne peuvent être contaminés ou contaminer les autres. Si de plus on met les malades en quarantaine suffisamment longtemps pour qu’ils guérissent et se débarrassent du virus, on peut l’éradiquer. Il est bien évident que dans le cas du SRAS-CoV-2, le but n’est plus de l’éradiquer, le nombre de personnes infectées étant trop grand et leur répartition géographique trop large. L’objectif est de diminuer au maximum le nombre de maladies sévères en attendant un vaccin.
L’immunité collective signifie qu’une partie suffisante de la population est exposée au virus et développe une réponse immunitaire pour que la chance qu’une personne non-exposée rencontre une personne contaminée soit très faible. Pour une grande partie des virus, la proportion requise de la population est légèrement supérieure à 80 %. À noter que ce principe d’immunité collective est un aspect clé des campagnes de vaccinations. Pour qu’une campagne tienne une maladie à distance, il faut qu’une certaine partie de la population se fasse vacciner. La construction d’une telle immunité collective va également de pair avec l’isolement des personnes vulnérables jusqu’à ce que le % requis de personnes immunisées soit atteint (personne ne suggère, comme on peut parfois le lire, que la stratégie de l’immunité collective signifie qu’il s’agit de laisser mourir un % de la population correspondant à l’IFR, à savoir près de 1 % de la population mondiale).
L’estimation du % de la population ayant développé une immunité contre l’infection par SRAS-CoV-2 varie selon les études entre 1 % et 25 %. Une étude suivant une cohorte à Genève a observé qu’elle croît de 3 % par semaine. Ce pourcentage est évidemment loin d’être suffisant pour qu’une société puisse se reposer sur une immunité collective. Cela signifie-t-il que l’idée d’une immunité collective est invalidée ? Pas du tout. Au mieux, cela reflète le succès des politiques d’isolement. Dans le long terme, les conséquences des politiques d’isolement pourraient dépasser les conséquences de l’infection par SRAS-CoV-2, surtout si une vaccination ou des traitements efficaces, curatifs ou prophylactiques, ne voient pas le jour bientôt.
L’important est de comprendre que les deux approches sont incompatibles et ne peuvent donc pas engendrer des conséquences permettant d’évaluer l’autre. De plus entre la quarantaine absolue et l’exposition non contrôlée, il existe un continuum de possibilité. Par exemple, une approche intéressante, basée sur le fait que Covid-19 est principalement sévère chez les sujets âgés ou possédant des comorbidités, est l’avalanche contrôlée, reposant sur des infections volontaires.
Ce billet n’aborde bien évidemment qu’une partie des concepts à l’origine des débats houleux sur Covid-19. Mais j’espère qu’il vous servira de point de départ pour explorer la diversité des opinions disponibles et éviter l’écueil du jugement à l’emporte-pièce. Tout le monde est dans le même bateau, et recherche la même chose, à savoir une résolution de cette crise avec le moins de victimes et de conséquences possibles.